VkSplat on Mip-NeRF 360 benchmark on NVIDIA RTX 3090, showing render from first eval view, time, VRAM, quality metrics, and number of Gaussians. VkSplat achieves consistent rendering quality while running >3.3x faster and using 33% less VRAM than CUDA+PyTorch baselines.
>3.3x
Speedup
vs. GSplat (CUDA+PyTorch)
−33%
VRAM Usage
Avg. on Mip-NeRF 360
3+
GPU Vendors
NVIDIA, AMD, & Intel® validated
// Abstract
Overview
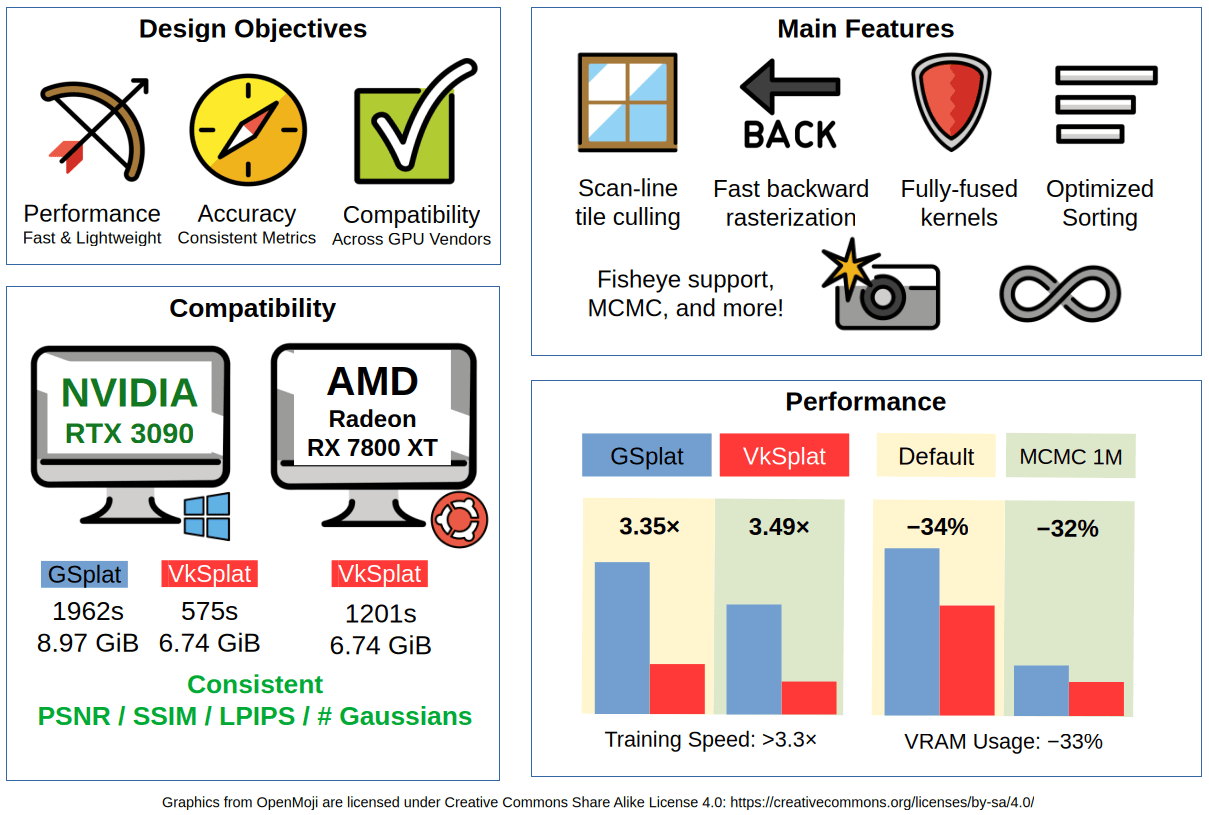
We present VkSplat, a high-performance, cross-vendor 3D Gaussian Splatting (3DGS) training pipeline implemented fully in Vulkan compute, addressing the performance and compatibility limitations of existing training pipelines. With various optimizations, we achieve >3.3x speed and 33% VRAM reduction over the CUDA+PyTorch baseline, maintaining rendering quality, and demonstrating compatibility across GPU vendors.
Our key contributions include complete tile culling using a parallelizable scan-line formulation, per-Gaussian and tensor-based rasterization backward passes that eliminate pixel-level atomic contention, and a fully-fused backward projection and Adam optimizer running in a single pass. To the best of our knowledge, this is the first fully-Vulkan-based 3DGS training pipeline that achieves state-of-the-art performance.
// Video
Training Demo
// Method
Technical Contributions
VkSplat is built on Slang-Gaussian-Rasterization and targets the Vulkan backend, leveraging Slang's multi-backend flexibility. Various optimizations push performance well beyond the CUDA baseline.
01
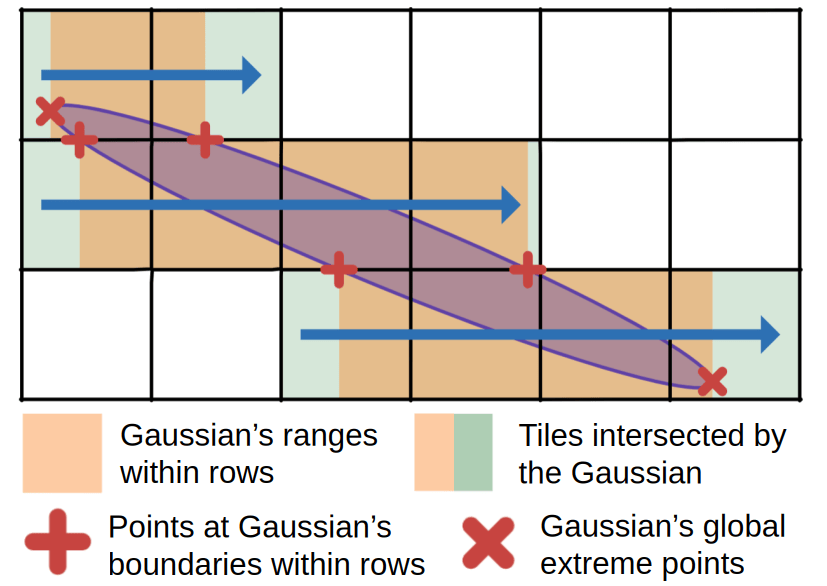
Complete Tile Culling
A scan-line intersection approach computes exact Gaussian–tile overlaps with closed-form interval arithmetic, eliminating both false-positive intersections that slow down sorting and rasterization in prior work, without introducing false-negative intersections that impact quality.
02
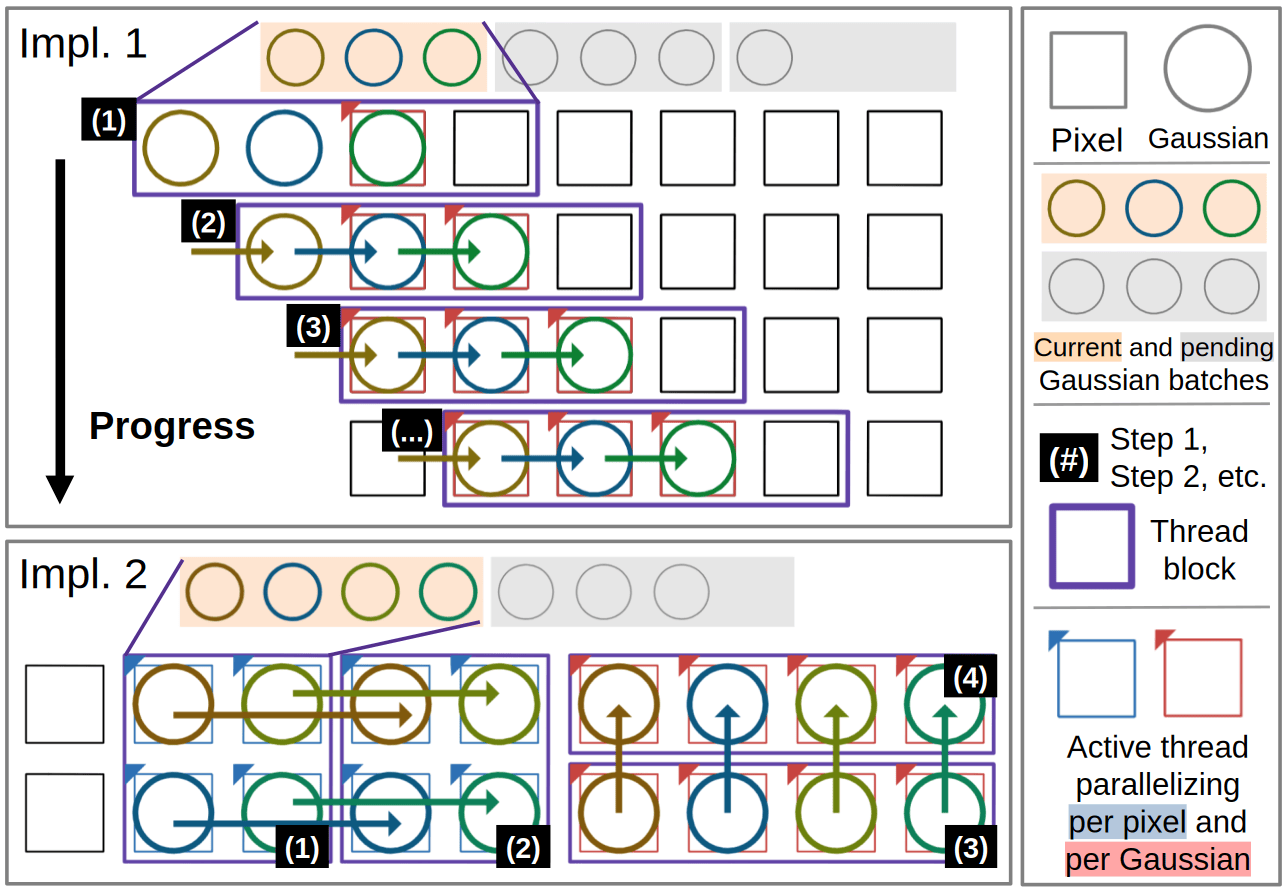
Adaptive Rasterization Backward
Two rasterization backward kernels (per-Gaussian parallelization and a shared-memory forward+backward formulation) are selected at runtime via Thompson sampling, choosing whichever is faster for the current scene configuration.
03
Fused Projection Backward & Optimizer
Projection backward and Adam optimizer are merged into a single kernel pass. Log/logit transforms and SH coefficient layout optimizations completely eliminate the excess VRAM footprint present in existing PyTorch-based implementations.
04
32-bit Tile-Depth Sorting
A depth-remapping function compresses tile-depth keys to 32 bits (14 bits tile ID + 18 bits depth), avoiding the slow Vulkan equivalent of CUDA's 64-bit radix sort while preserving quality at up to 1080p resolution.
05
Fully-Fused Loss Gradient
A fused kernel computes the gradient of the weighted L₁ + SSIM loss directly, skipping all intermediate reductions and memory-layout conversions. Reference images are stored as 4×UINT8 RGBA, removing the FP32 conversion overhead.
06
Optimized SH Memory Layout
Degree-3 spherical harmonics (48 FP32 coefficients per Gaussian) are split into 12 × 128-bit values in a column-aligned format matching subgroup size, improving memory coalescing across the projection stages.
Existing implementations often produce false-positive intersections in tile-Gaussian association, which negatively impacts performance. In our implementation, we compute exact intersections using a scan-line approach, with efficient intersection counting and traversal in fused kernels.
Backward rasterization is often a performance bottleneck of 3DGS training. We use two implementations with careful consideration to minimize atomic contention and minimizing divergence, and a Thompson sampling scheduler to automatically pick the fastest implementation per dataset and hardware.
// Results
Quantitative Results
We evaluate on 7 scenes from the Mip-NeRF 360 dataset. Each configuration is trained 5 times; results are reported with 90% confidence intervals. VkSplat matches baseline quality while achieving substantial resource savings.
Quality Metrics (Mip-NeRF 360, mean over 7 scenes)
Method
PSNR ↑
SSIM ↑
LPIPS ↓
# Gaussians
GSplat (Default)
29.[19–25]
0.87[8–9]
0.124
3.0[6–8] M
VkSplat (Default) Ours
29.2[0–7]
0.87[8–9]
0.12[4–5]
3.0[2–6] M
GSplat (MCMC)
29.4[3–5]
0.881
0.1[29–30]
1.00 M
VkSplat (MCMC) Ours
29.[39–45]
0.881
0.130
1.00 M
Resource Usage (NVIDIA RTX 3090)
Method
Total Time
Speedup
VRAM (GiB)
GSplat (Default)
1384 s
—
4.56
VkSplat (Default) Ours
412 s
3.35×
3.01
GSplat (MCMC)
995 s
—
1.37
VkSplat (MCMC) Ours
285 s
3.49×
0.93
All timing on NVIDIA RTX 3090, averaged over 7 Mip-NeRF 360 scenes. VkSplat is faster in every single pipeline stage.
Per-Stage Timing Breakdown
Default densification. Average over 7 scenes, NVIDIA RTX 3090.
GSplatVkSplat
Projection Fwd
94 s
19 s
Tiling/Sorting
42 s
25 s
Rasterize Fwd
69 s
25 s
Loss
103 s
32 s
Rasterize Bwd
246 s
130 s
Proj Bwd + Optim
459 s
131 s
Densification
31 s
5 s
Unaccounted
341 s
43 s
VkSplat outperforms GSplat in every pipeline stage. The large "unaccounted" time in GSplat is mainly SH tensor concatenation backward and small kernel launches managed by PyTorch.
Visual Comparison
VkSplat produces rendering quality consistent with the CUDA baseline across Mip-NeRF 360 dataset. It also generalizes to other commonly used benchmark datasets with pinhole and fisheye cameras. First eval image is shown for each dataset.
GSplat (garden, default)
VkSplat (garden, default)
GSplat (counter, MCMC 1M)
VkSplat (counter, MCMC 1M)
VkSplat (truck, MCMC 1M)
VkSplat (playroom, MCMC 1M)
VkSplat (LLFF fern, MCMC 1M)
VkSplat (Zip-NeRF nyc, MCMC 3M)
// Cross-Vendor
GPU Compatibility
A key advantage of building on Vulkan is freedom from the NVIDIA/CUDA ecosystem. VkSplat has been validated on NVIDIA, AMD, and Intel® hardware, producing consistent quality metrics and VRAM usage on both vendors. All Gaussian counts and quality scores are identical between platforms.
NVIDIA RTX 3090
575 s
Bicycle scene, default densification
AMD Radeon RX 7800 XT
1201 s
Bicycle scene, default densification
The largest performance gap between the two vendors is image-to-device transfer, which is roughly 30× slower on AMD due to a PCIe throughput difference. Asynchronous data transfer would largely close this gap. Compute-bound stages like rasterization backward are within 2× of each other. We expect hardware-specific tuning could further reduce the gap.
// Discussion
Limitations & Future Work
While VkSplat demonstrates strong performance advantages, the current implementation has several limitations compared to production-grade 3DGS trainers:
Missing practical features: Exposure correction, depth/normal supervision, image batching, and multi-GPU training are not yet implemented.
Densification strategies: Only default and MCMC densification are supported; more efficient alternatives like those in Taming 3DGS or LiteGS are not yet integrated.
AMD performance gap: The current PCIe transfer bottleneck on AMD could be mitigated with asynchronous data transfer.
Future extensions include support for additional Slang backends (Metal, DirectX, WebGPU) and application of VkSplat's optimizations to other Gaussian splatting variants.
// Citation
BibTeX
@inproceedings{chen2026vksplat,
booktitle = {Eurographics 2026 - Short Papers},
title = {{VkSplat: High-Performance 3DGS Training in Vulkan Compute}},
author = {Chen, Jingxiang and Ibrahim, Mohamed and Liu, Yang},
year = {2026},
publisher = {The Eurographics Association},
ISSN = {2309-5059},
ISBN = {978-3-03868-299-8},
DOI = {10.2312/egs.20261024}
}
// Acknowledgements
Acknowledgements
We thank the authors of GSplat and Slang-Gaussian-Rasterization for open-sourcing their codebases under permissive Apache-2.0 license, which served as the foundation for our work. We also thank the original 3DGS authors for releasing their implementation, as well as the Mip-NeRF 360 dataset.
This work was conducted at Huawei Canada. The website template is inspired by the NeRF/3DGS project page conventions from the community.